Text-To-Image Context#
Data#
Text & Images#
CLIP (Contrastive Language-Image Pre-training) is a dual-encoder model that learns from hundreds of millions of image–caption pairs. It turns each picture and each sentence into a vector, trains so that matching pairs land close together in a shared mathematical space.
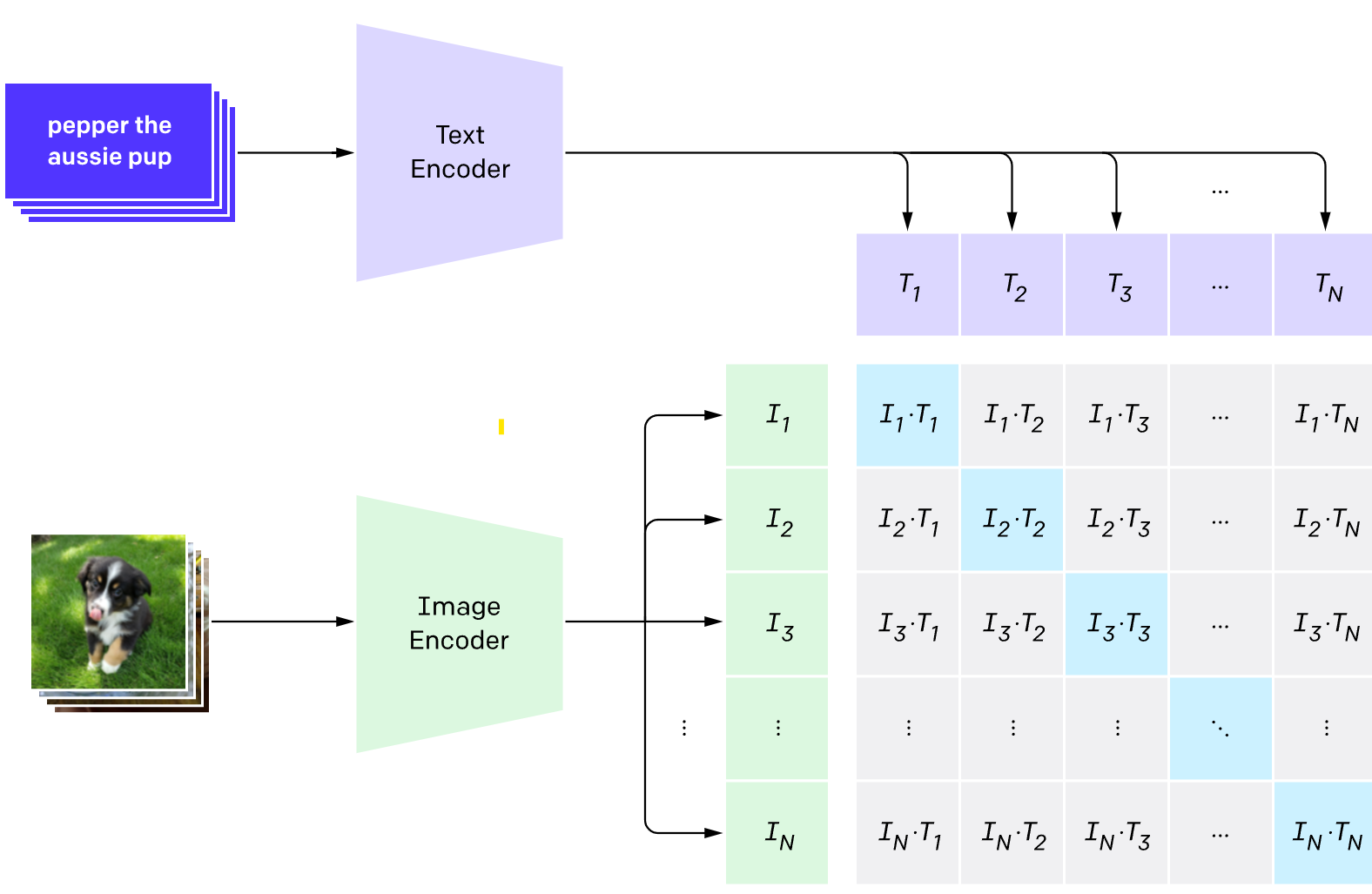
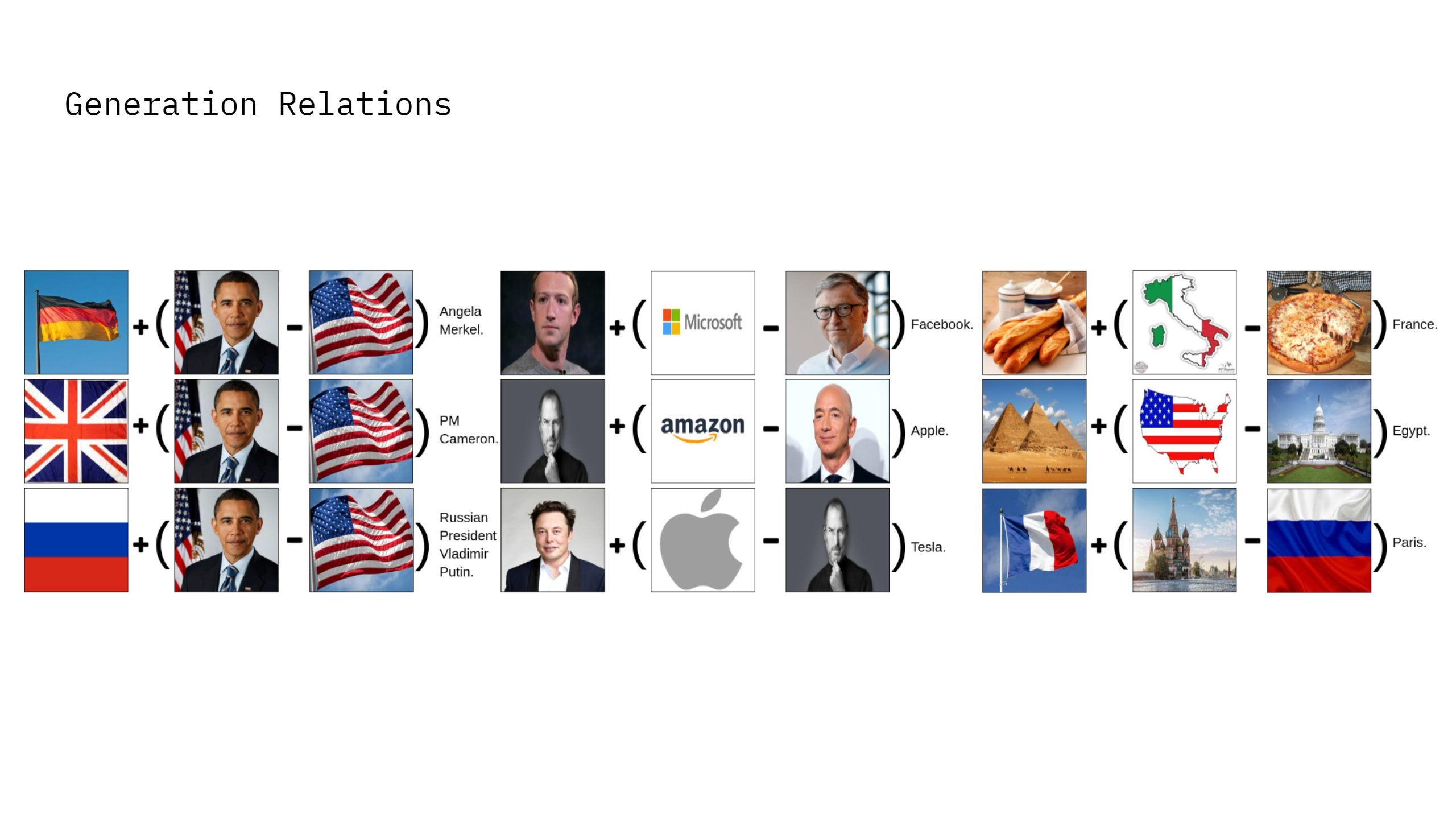
This shared space enables semantic calculations using simple arithmetic combinations of embeddings.
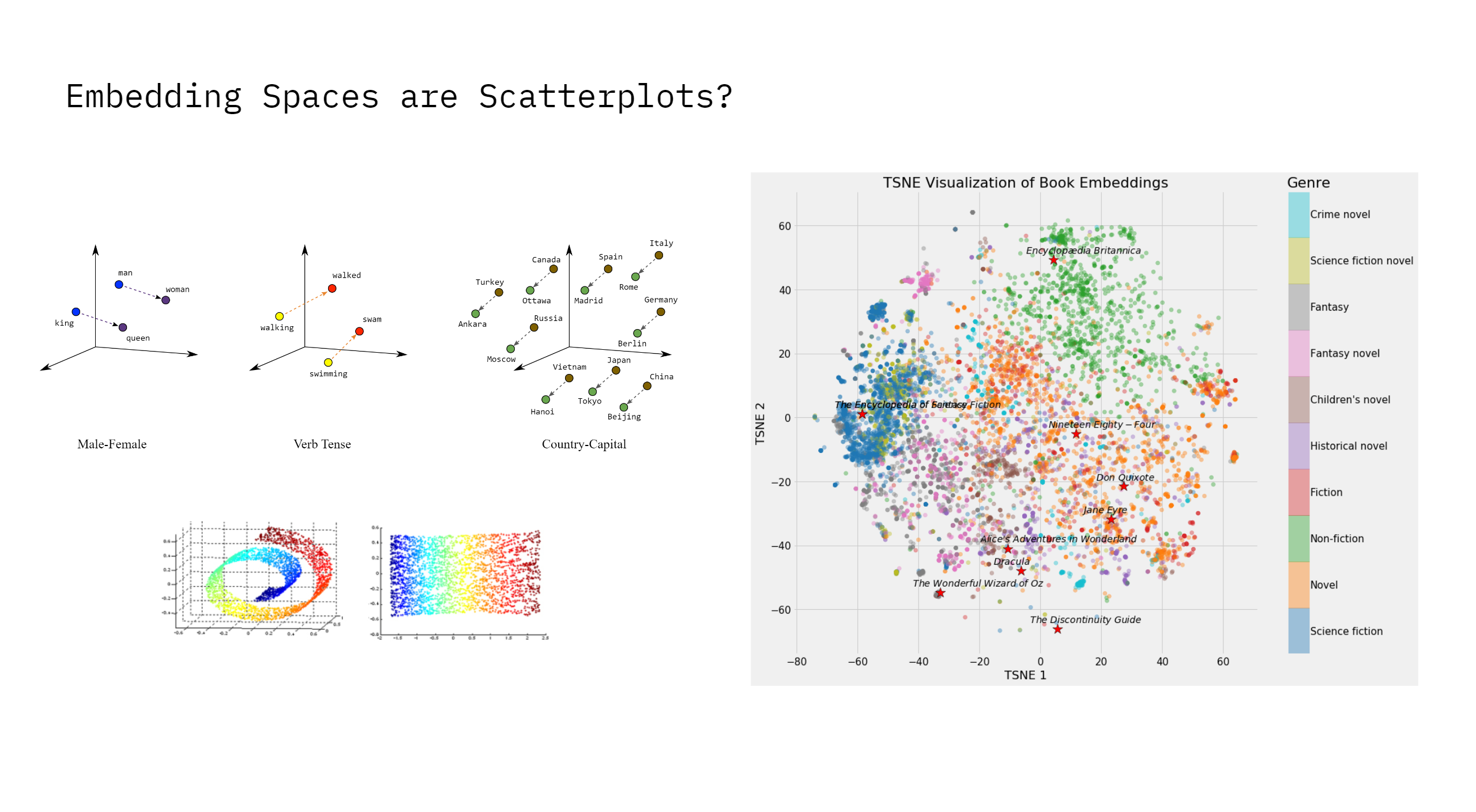
What are embedding-spaces?#
Stable Diffusion#
Stable Diffusion is an open-source text-to-image latent diffusion model: it starts with random noise in a compact latent space, repeatedly removes that noise according to guidance from a CLIP-encoded text prompt.